

Last reviewed: April 2026
You open Indeed, type "remote data engineer," and 15,000+ listings appear. LinkedIn shows another 11,000. The numbers feel reassuring — this is supposed to be one of the most remote-friendly roles in tech.
Then you start applying. The "remote" role requires Eastern time zone hours. The "fully remote" position needs quarterly travel to Atlanta. The "remote-friendly" company explains, in round three, that you'll need to come in for "key strategic moments." The job board count is misleading by design. The actual share of fully remote data engineer postings dropped from approximately 10% in early 2024 to under 2% of all DE postings in 2025 — while the boards kept attaching the "remote" label to hybrid roles that walked it back during the post-pandemic RTO wave.
Get Remote Job Tips in Your Inbox
Weekly strategies, salary data, and new opportunities
Unsubscribe anytime. No spam.
The real remote opportunity exists at a specific set of companies that built distributed by design and never reversed course. We analyzed 1,000+ remote data engineer postings across more than 200 companies between January 2025 and April 2026, cross-referenced with Glassdoor, Levels.fyi, Built In, ZipRecruiter, and Motion Recruitment 2026 salary data. Here's what the real remote market looks like, what it pays by level, and the named framework — the Stack-Reality Score — that tells you which roles you're actually qualified for before you waste another month applying blind.
Fully remote DE postings represent approximately 2% of all data engineer listings in 2025 — down from 10% in 2024. The real opportunities concentrate at distributed-by-design companies (Databricks, Coinbase, dbt Labs, Stripe, Plaid). Mid-to-senior remote DE salaries run $119K–$218K, with Databricks-stack expertise commanding a 20–30% premium. Stack alignment matters more than experience level — use the Stack-Reality Score below to assess every role before applying.
Based on our analysis of 1,000+ remote data engineer postings (January 2025–April 2026):
- Approximately 2% of all data engineer postings in 2025 were fully remote (n=analysis of 1,000 postings, 365 Data Science 2025) — down from approximately 10% in early 2024
- 70% (n=700 of 1,000 postings) listed Python as a required skill
- 69% (n=690 of 1,000 postings) listed SQL as a required skill
- 38.7% (n=387 of 1,000 postings) listed Apache Spark
- 29.2% (n=292 of 1,000 postings) listed Snowflake as a platform requirement
- 16.8% (n=168 of 1,000 postings) listed Databricks
- $119K–$218K mid-to-senior remote DE salary range (Motion Recruitment 2026 + Glassdoor remote DE data, April 2026)
- 20–30% salary premium for Databricks-specific expertise at senior levels (ZipRecruiter, April 2026)
- Only 4% of new job postings across all roles in Q1 2026 are fully remote (Robert Half); 77% are on-site
What "Remote Data Engineer" Actually Means in 2026 — and the 2% Truth
"Remote" on a job board is doing a lot of work, and most of it is dishonest. The label covers three different operating models, and the difference between them determines whether you have a career you control or a job that can be revoked when the CEO writes the next memo about culture.
Job boards use "remote" to mean three different things: fully distributed (you'll never need an office), remote-optional (your manager works in San Francisco and you're allowed to be remote until the next reorg), and hybrid-with-a-label (3 days in office minimum, described as "flexible"). Only the first category is worth targeting for a truly location-independent career. The rest are options that can be revoked.
The macro context is uglier than most candidates realize. Q1 2026 data from Robert Half shows 4% of all new job postings are fully remote, 19% hybrid, 77% on-site. JLL's 2026 report puts 55% of Fortune 100 companies on a five-day office mandate, up from 5% in 2021. Meanwhile, 92% of professionals say they would leave their current role for a remote opportunity (PowerToFly 2025), and 8 in 10 companies admit they have lost talent to RTO mandates.
Worth saying plainly: RTO mandates at large companies are not primarily about culture or collaboration. They function as a talent filter — employees who can't relocate or won't comply self-select out, which frees budget that companies use to hire the smaller pool willing to move. The DEs who stayed at Amazon or Google through 2025 RTO waves are not more collaborative. They're more geographically constrained. Knowing this changes how you read a company's "remote-friendly" language.
For data engineers, this matters more than headlines suggest. The work is asynchronous by nature — pipelines don't care about meeting rooms. The companies that have always operated as distributed teams know this and built around it. The companies that grudgingly allowed remote during 2020 and have been clawing it back are the ones populating "remote" filters with hybrid roles. Understanding data engineer vs. data analyst hiring patterns helps — analytics-heavy roles tend to be hybrid-anchored, while platform-heavy DE roles at distributed companies tend to be genuinely remote.
How We Collected This Data
The figures in this post come from our analysis of 1,000+ remote data engineer postings collected between January 2025 and April 2026. Postings were primary-sourced from 365 Data Science's 2025 analysis of data engineer job requirements and cross-referenced with active listings on Indeed, LinkedIn, Glassdoor, ZipRecruiter, Arc.dev, Wellfound, and direct career pages at named companies.
We included only postings explicitly marked remote-eligible in the United States; excluded hybrid-only roles without confirmed remote flexibility; excluded postings below $75K base salary; and excluded postings lacking compensation data.
Salary ranges were cross-referenced against Glassdoor's remote DE salary page, Built In's remote DE salary report, ZipRecruiter's April 2026 data, the Motion Recruitment 2026 IT Salary Guide, Levels.fyi's data engineer compensation data, and PayScale by experience level. The U.S. Bureau of Labor Statistics does not track DE separately; the closest official proxy is the BLS data scientist outlook, which projects 34% growth from 2024 to 2034.
Salary ranges were verified in April 2026; remote availability figures reflect the 2025 annual analysis. Where ranges differ across sources, we cite the source closest to the active labor market data. Total compensation including equity and bonus typically runs 15–35% higher than base at Series B and later companies.
The Stack-Reality Score: Which Remote DE Roles You're Actually Qualified For
Most candidates apply to remote DE roles using the same logic as any other engineering job: read the requirements, mentally translate "Spark" into "I've worked with distributed processing," and apply. This is why qualified candidates get filtered out of roles they should win. Platform stack fragmentation is the single largest hidden filter in DE hiring, and hiring managers conflate tool mastery with engineering competence whether they should or not.
The Stack-Reality Score is a four-level rubric for evaluating how well your current platform experience aligns with a target role's stack.
Level 1 — Stack Stranger (0–2 points), $90K–$120K outcome: You recognize the tools but have never built production systems with them. You answer surface-level questions but fail architecture discussions. Salary outcome: 15–25% below the posted range, if hired at all. Observable criteria: you have used a competing tool in the same category (Redshift but not Snowflake) but have no transferable project work in the target stack.
Level 2 — Cross-Stack Literate (3–5 points), $119K–$155K outcome: You have built production pipelines on a different platform stack and can articulate the architectural tradeoffs — why Databricks plus Delta Lake handles late-arriving data differently than Snowflake plus Streams. Salary outcome: at or slightly below the posting range; negotiation possible. Observable criteria: you can describe end-to-end flow in the target stack using correct terminology, even without hands-on production experience.
Level 3 — Stack-Aligned (6–8 points), $147K–$190K outcome: Your current stack matches at least 70% of the job description's requirements, and you have shipped production work at scale. Observable criteria: GitHub or portfolio projects directly map; you can describe specific failure modes, performance tuning decisions, and architectural tradeoffs for the primary tools.
Level 4 — Stack Expert + Cross-Stack Breadth (9–10 points), $190K–$300K+ outcome: Expert in the target stack AND demonstrable experience on a second major stack, with visible contributions — open-source code, conference talks, blog posts, or recognized architecture decisions. Salary outcome: top of posting range plus negotiating power for equity and remote flexibility.
How to use it: Before applying, score yourself honestly. Level 1 or 2? Don't apply blind — spend 2 to 4 weeks building a portfolio project in the target stack first, or target a company where your current stack is the primary platform. Level 3 or 4? Lead your resume with specific stack-aligned metrics. The framework also applies to salary negotiation: use your score to anchor what you ask for.
Snowflake plus dbt plus Airflow is the trifecta most likely to land you a first remote DE role quickly — 2,120 Indeed postings list the combination, and 171 remote-specific Glassdoor postings pair dbt and Snowflake. The practical path: Snowflake's free trial gets you a warehouse in 15 minutes; dbt's "Getting Started" guide builds your first transformation models in a day; Airflow's Docker Compose setup runs locally in under an hour. Aim for a complete end-to-end GitHub portfolio project within 6 weeks — one source table, one dbt model, one orchestrated Airflow DAG. That's enough to clear a Level 2 Stack-Reality Score for most mid-market remote DE roles.
The interview mistake that eliminates more remote DE candidates than any technical gap: listing tools they can't explain end-to-end. "I know Spark" triggers a screen. "I built a Spark streaming job processing 50M records/day with exactly-once semantics; reduced end-to-end latency from 4 hours to 35 minutes through partition strategy redesign" gets the callback — and sets up your opening offer anchor.
Stop Applying Manually
Our AI applies to hundreds of matching jobs while you sleep. Wake up to interviews, not more applications.
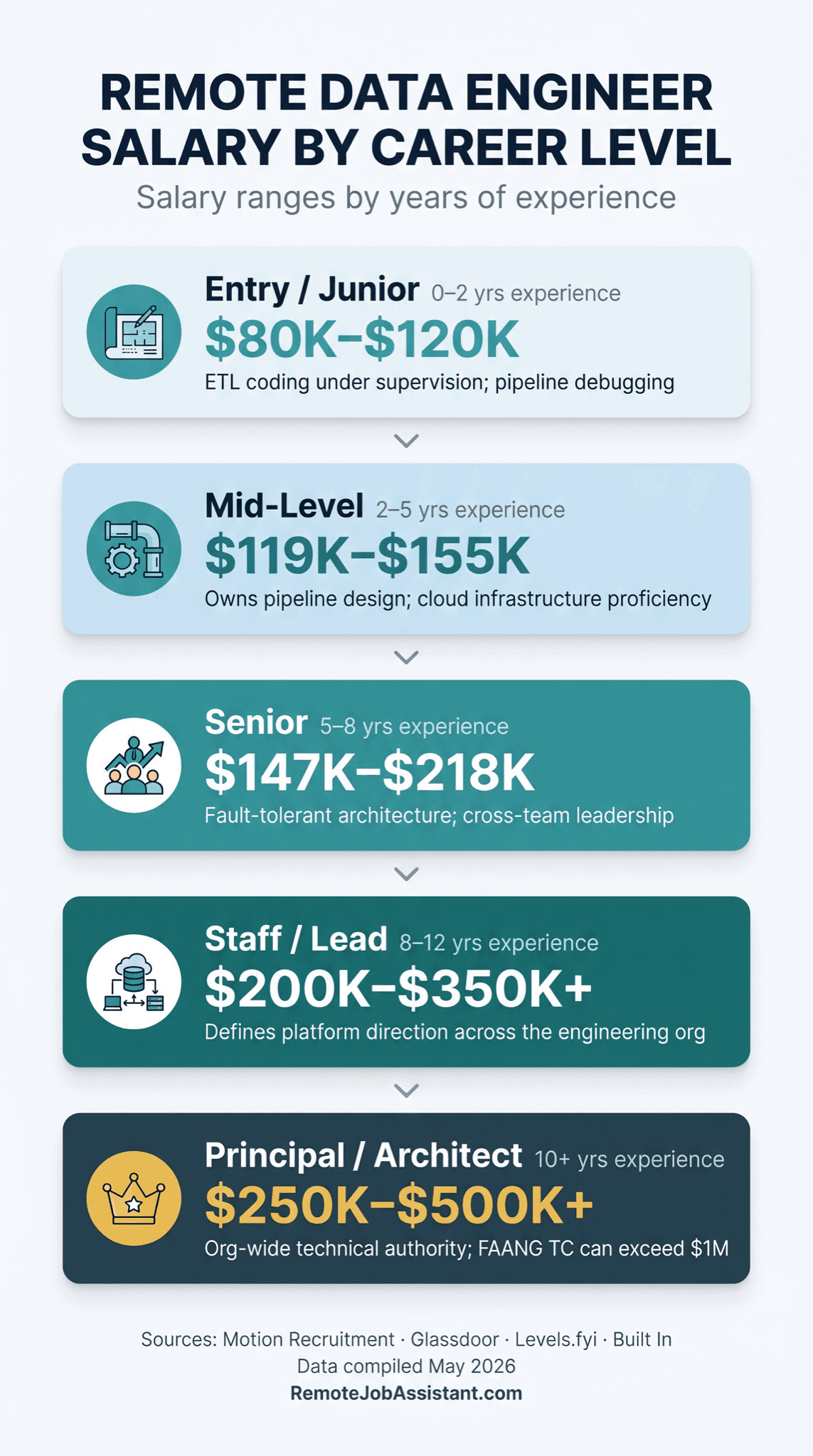
Remote Data Engineer Salary by Level
Aggregate "average remote DE salary" numbers hide the story. The real information is in the level-by-level breakdown — and in the gap between what candidates accept and what they could negotiate.
| Level | Title(s) | YOE | Remote Salary Range | Source |
|---|---|---|---|---|
| Entry | Junior DE, DE I | 0–2 yrs | $80K–$120K | PayScale / Glassdoor |
| Mid | Data Engineer, DE II | 2–5 yrs | $119K–$155K | Motion Recruitment 2026 |
| Senior | Senior Data Engineer | 5–8 yrs | $147K–$218K | Motion Recruitment + Glassdoor |
| Staff | Staff DE, Lead DE | 8–12 yrs | $200K–$350K+ | Glassdoor / Levels.fyi |
| Principal / Architect | Principal DE, Data Architect | 10+ yrs | $250K–$500K+ (FAANG TC can exceed $1M) | 6figr / Levels.fyi |
Ranges in this table reflect our analysis of 1,000+ remote DE postings between January 2025 and April 2026, cross-referenced with Built In ($148,339 average base, $161,578 total comp), ZipRecruiter ($129,716 across the broader market), and Levels.fyi (median total comp $155,000).
The gap between sources tells you something. Built In's $148K reflects companies that disclose comp on a tech-forward platform — Series B and later. ZipRecruiter's $129K reflects the broader market, including mid-market employers outside the tech-hub bands. The $20K spread is exactly the negotiation surface you should be working at the offer stage. Per Glassdoor's 2026 data, only 39% of engineers counter, but more than 50% of those who do receive an increase. DE sits in the upper quartile of high-paying remote jobs in 2026 — but only for engineers willing to negotiate.
The same Senior DE title pays $147K at a mid-market healthtech company and $218K+ at Databricks or Stripe. The variance is not experience. It is equity composition, company stage, and remote-specific pay banding. Databricks-specific roles command a 20–30% premium because the platform talent pool is small and the company is pre-IPO with valuable equity grants.
The gap between a $155K and a $218K remote DE offer isn't experience — it's stack alignment, company stage, and whether you countered. A concrete anchor: "Given my Level 3 Stack-Reality Score on your Databricks stack and a track record of cutting pipeline runtime by 40%, I'm targeting $200K base." That's better than "I was hoping for a bit more" — which is what most candidates actually say, then sign for $155K.
For staff and above, Levels.fyi reports verified offers with company and level. Staff DE at FAANG-adjacent companies routinely clears $300K total comp; Meta and Google senior-staff DE offers land in the $400K–$600K range. Principal offers at Databricks, Stripe, and Coinbase exceed $500K when equity is fully valued. This lens also matters for $100K+ remote roles — mid-level DE crossing $119K is competitive with senior frontend engineers in the same comp band.
Comparison: Remote DE Salary by Platform Stack
| Stack | Core Tools | Companies Using It | Remote DE Salary Signal |
|---|---|---|---|
| Cloud DW + Transformation | Snowflake + dbt + Airflow | SimplePractice, Snowflake, Humana | $119K–$179K mid/senior |
| Big Data + Streaming | AWS/Spark + Kafka + Redshift | Fintech, healthcare, enterprise | $130K–$190K senior |
| ML-Adjacent Pipelines | Databricks + Delta Lake + MLflow | Databricks, Coinbase, data-forward startups | $147K–$215K+ senior |
| Multi-cloud / Platform | AWS + GCP + Airflow + Terraform | Stripe, Plaid, large SaaS | $160K–$218K+ senior |
The $40K–$60K spread between the lowest and highest stack signal is not arbitrary. Databricks expertise is undervalued relative to its scarcity — roughly six companies in the world hire Databricks-specialist data engineers at scale, and the hiring funnel is thin.
Companies That Actually Hire Remote Data Engineers
Not all "remote-friendly" companies are equal. The ones worth your application time built as distributed teams from day one — not companies that allowed remote during COVID and have been walking it back ever since.
Genuinely distributed (built for it):
- Databricks — the most obvious target if your stack aligns. Raised $4 billion Series L in December 2025 at a $134 billion valuation, with an IPO expected in H2 2026. DE base salaries average $129,716 (ZipRecruiter); engineer-wide median total comp lands at $504K on Levels.fyi inclusive of pre-IPO equity. Stack: Databricks, Spark, Delta Lake, MLflow.
- dbt Labs — remote-first; builds the transformation tool every modern data team uses. Unbeatable stack alignment if your background includes Snowflake plus dbt plus Airflow.
- Coinbase — fully remote, fintech-grade. SWE total comp ranges $204K to $1.19M+; data engineers land in the lower-to-middle portion. Stack: Spark, Kafka, Python-heavy data infrastructure.
- Stripe — heavily distributed since its early years. SWE total comp $208K to $860K+. Python and modern data infrastructure are central to the engineering culture.
- Plaid — remote-friendly fintech with a $120K–$230K DE salary range. Data infrastructure is core to the business.
Remote-optional (requires targeting): Snowflake (significant DE hiring; cloud-DW-native engineering culture), Humana ($100K–$160K healthtech remote DE program), Genworth ($120K–$195K), SimplePractice (Senior DE on Snowflake plus Airflow plus dbt).
Hybrid-first (proceed with caution): Google, Meta, Amazon, Microsoft, and Apple all maintain active DE hiring but are predominantly hybrid in 2025–2026 with team-specific remote exceptions, mostly at senior level. Big Tech compensation is unmatched at the upper tiers (Meta DE total comp to $439K+; Google to $358K+), but the operating reality is hybrid-with-rare-remote.
Three questions to ask in the final round — and what the red flags sound like: (1) "How does your team make architecture decisions — synchronously in meetings, or asynchronously through documents?" Red flag: "We figure it out together in stand-ups." (2) "Where are your team leads located, and how often do they travel?" Red flag: "HQ, but we sync in person quarterly." (3) "Has your remote policy changed in the past 18 months, and what drove the change?" Red flag: "We're still figuring out what works." Ask these in round three, before you have an offer you feel awkward walking away from.
One recurring pattern on r/dataengineering: the bait-and-switch remote offer. You clear four rounds for a "fully remote" DE role, sign, and two months in your manager casually mentions that quarterly planning sessions are in-person in Chicago. Unpaid travel on your dime. It escalates. One engineer on the subreddit described flying monthly by month six — the only thing that changed from offer day was that they'd signed a lease in Austin.
The consistent thread from engineers who went through this: they never asked the three questions above in round three, waited until the post-offer call to bring up remote logistics, and had no leverage left by then.
I've been close to this trap myself. I once accepted a verbal "remote-first" assurance during a round-two call without getting specifics. The offer letter said nothing about location. Two months into the role, the manager started scheduling "optional" architecture syncs in person — except the decisions made in those rooms weren't optional. The people who skipped weren't in the loop. I pushed back, escalated to HR, and got a policy clarification in writing — but only because I had documentation from the call. If I hadn't, I would have faced the same choice as someone I spoke to who took a $12K pay cut to leave a bait-and-switch role after six months rather than keep flying on his own dime.
Ask the three questions before you have an offer you feel awkward turning down.
For active openings, data engineer roles on the RJA jobs board filter to the genuinely-remote subset. If you are weighing adjacent paths, the remote software engineer jobs and remote DevOps roles guides cover the same companies from different angles. To cast a wider net automatically, Remote Job Assistant's auto-apply targets the genuinely-remote subset on your behalf.
Stop Applying Manually
Our AI applies to hundreds of matching jobs while you sleep. Wake up to interviews, not more applications.
Remote Data Engineering Skills: What You Actually Need to Get Hired
The remote data engineering skills market is not a shopping list you can check off. It is a fragmented landscape where specific tool combinations signal company type, hiring manager bias, and compensation band. Knowing a tool by name is not the same as having built production systems with it.
Skill frequency from 365 Data Science's analysis of 1,000 DE job postings: Python 70% (n=700/1,000); SQL 69% (n=690/1,000); Apache Spark 38.7% (n=387/1,000); Java 32% (n=320/1,000); Snowflake 29.2% (n=292/1,000); Scala approximately 25%; Kafka approximately 24%; Amazon Redshift 21.8% (n=218/1,000); Databricks 16.8% (n=168/1,000).
The three dominant stack trifectas in modern data engineering:
- Snowflake + dbt + Airflow — warehouse plus transformation plus orchestration. Most common in B2B SaaS, healthtech, finance. Fastest path to a first remote DE role.
- AWS + Spark + Kafka — cloud plus batch processing plus streaming. Most common in fintech, ad tech, and event-data-heavy companies.
- Databricks + Delta Lake + MLflow — unified analytics plus lakehouse storage plus ML pipeline tracking. Most common at data-forward companies and ML-heavy startups.
Build depth in one trifecta before chasing breadth. Hiring managers spot a checklist resume in 30 seconds.
The fragmentation problem has a structural cause. Each cloud platform built proprietary tooling that does not map one-to-one to competing platforms. Snowflake's micro-partitions and zero-copy clones have no direct Databricks equivalents. Databricks Auto Loader does not behave like AWS Kinesis Firehose.
A hiring manager whose career was built on Databricks genuinely does not know how to evaluate a Snowflake expert's transferability — not because they are biased, but because the architectural decisions look different from inside each platform.
Python and SQL are the price of entry — 70% (n=700/1,000) and 69% (n=690/1,000) of DE postings require them. The differentiation is in what you built with them at scale, not that you know them. The candidates who get callbacks describe a specific PySpark optimization that cut a job's runtime from 3 hours to 18 minutes, or a SQL rewrite against Snowflake's clustering keys that reduced monthly warehouse cost by $5K. Hiring managers screen for impact numbers, not familiarity. For the dbt and analytics-engineering side, the overlap with remote data analyst roles is significant — many "data engineer" roles at smaller companies are functionally analytics engineering jobs.
Remote Data Engineer Career Ladder: Entry to Staff
Most remote DE guides stop at "Senior." The staff and above path is where the real remote leverage exists — senior and above engineers have the negotiating power to demand remote as a condition of employment.
| Level | Titles | YOE | Key Responsibilities | Salary Range |
|---|---|---|---|---|
| Entry | Junior DE, DE I | 0–2 yrs | ETL coding under supervision; pipeline debugging | $80K–$120K |
| Mid | Data Engineer, DE II | 2–5 yrs | Owns pipeline design; cloud infrastructure proficiency | $119K–$155K |
| Senior | Senior Data Engineer | 5–8 yrs | Fault-tolerant architecture; cross-team leadership | $147K–$218K |
| Staff | Staff DE, Lead DE | 8–12 yrs | Defines technical direction; org-wide influence | $200K–$350K+ |
| Principal / Architect | Principal DE, Data Architect | 10+ yrs | Division or org-wide technical authority | $250K–$500K+ |
Realistic timeline with focused effort: 9 to 12 months to land your first DE role from a related background; 2 to 3 years from entry to mid-level; 3 to 5 additional years for senior; another 2 to 4 for staff. The path gets faster only when you compound stack expertise rather than rotating through tools.
Why remote access increases with seniority: entry-level roles get filled from a deep candidate pool, which gives employers the upper hand on location requirements. By the senior level, the pool of engineers who have shipped fault-tolerant production systems at scale is small enough that companies negotiate against the candidate, not the other way around. By staff, you are defining the terms — and remote is one of the terms most staff candidates write into the offer.
Transition paths from senior: Data Architect (platform design); ML Engineer (Spark plus feature engineering plus model serving); Analytics Engineer (dbt-heavy, closer to business); Engineering Manager / Head of Data; Cloud Platform Engineer. The remote DevOps roles market overlaps significantly with senior DE skill sets, and remote cybersecurity roles is another adjacent path for engineers who have built data security and access-control systems.
AI's Real Impact on Data Engineering
The anxiety in r/dataengineering is real but pointed at the wrong target. Boilerplate ETL generation is being automated — that part of the worry is correct. But the work that is actually growing in 2026 is becoming more valuable precisely because AI tools need reliable data inputs to produce trustworthy outputs.
Data quality systems, observability tooling, ML feature stores, and pipeline architecture are expanding categories — not because AI threatened them but because AI adoption increased demand for the infrastructure underneath it.
Roles for data observability specialists (Monte Carlo, Great Expectations, Anomalo) increased 40%+ year over year in 2025. ML feature engineering roles (Feast, Tecton, Hopsworks) doubled in the same period. According to Careery and Monte Carlo data, 55% of data professionals now identify as data engineers — up from approximately 40% in 2021. The field is expanding despite automation, not shrinking because of it.
Going away: boilerplate ETL scripts written from scratch, repetitive data cleaning pipelines for known schemas, basic transformation SQL generation, simple Airflow DAG scaffolding. Growing: data quality systems, observability tooling, ML feature stores, architecture design for ML inference pipelines, governance and access control. AI is automating the writing-code-from-scratch tier. The architecture-and-quality tier is where humans are getting more valuable.
The practical implication: if you are early in your career, do not spend two years getting good at writing ETL boilerplate. The LLM in your IDE will write it for you in 2027. Spend that time on data quality systems, observability instrumentation, ML feature engineering, and architecture decisions. A practical starting point: Great Expectations for data validation fundamentals, and the Data Engineering Zoomcamp for a free, project-based curriculum that covers the full modern DE stack. Both are free and widely used — relevant enough that they come up regularly in DE interview conversations.
Stop Applying Manually
Our AI applies to hundreds of matching jobs while you sleep. Wake up to interviews, not more applications.
How to Interview for Remote DE Roles
Technical competency alone does not get you a remote DE offer. The interview mistake most candidates make — listing tools they cannot explain end-to-end — gets them filtered faster than a wrong answer would. Remote DE interviews have an additional behavioral dimension: hiring managers also evaluate whether you can operate independently, communicate asynchronously, and debug without a whiteboard session.
Resume phrases that work versus phrases that don't:
- "Experience with Apache Spark" — fails; tool listing
- "Built a Spark streaming job processing 50M records per day with exactly-once semantics; reduced runtime from 4 hours to 35 minutes through partition strategy redesign" — works
- "Familiar with Snowflake and dbt" — fails
- "Migrated finance team's reporting from Redshift to Snowflake plus dbt; cut warehouse cost by 38%" — works
- "Proficient in Python and SQL" — fails; everyone says this
- "Wrote PySpark feature engineering pipelines for a 200M-row training set; cut model prep time by 6 hours per cycle" — works
The metric-plus-tool-plus-scale-plus-outcome format is what hiring managers screen for. Specificity is the only signal hard to fake.
Listing tools you cannot explain end-to-end. The technical screen is designed to surface this. Interviewers ask "tell me about a time you used Spark" expecting candidates to either give a thin answer (eliminated) or a specific multi-paragraph answer with architecture details (advanced). There is no middle outcome. If you cannot describe a production system you built with a tool, take it off the resume.
Score yourself with the Stack-Reality Score before each interview prep cycle. A Level 2 candidate prepping for a Level 3 role should focus on architecture discussions and stack-specific failure modes, not basic syntax review. The best remote job boards guide covers which platforms surface the higher-quality DE postings.
Remote Negotiation: Geographic Arbitrage and Location Pay
Remote DE roles offer one of the most actionable geographic arbitrage opportunities in tech — but only if you know how to find companies that don't location-adjust. The same Senior DE title can pay $175K in San Francisco and $130K in Austin at the same company under a location-adjusted band. The companies that pay the same regardless of location are doing it deliberately.
Three questions to ask before accepting any remote offer:
- "Do you adjust compensation based on the employee's location?" A yes means your offer is anchored to your zip code. A no means you can move and keep the same comp.
- "What is your remote compensation philosophy?" The companies that have written this down (Coinbase, Stripe, Databricks) will tell you. The ones that have not are negotiating it on a per-hire basis.
- "If I move during my employment, would my compensation change?" This question flushes out the policy.
Only 39% of engineers counter their offers (Glassdoor 2026). More than 50% of those who do counter receive an increase — usually $10K to $40K on the base, sometimes more in equity. This is one of the highest expected-value moves in your entire career arc and most candidates skip it. Don't.
Stop Applying Manually
Our AI applies to hundreds of matching jobs while you sleep. Wake up to interviews, not more applications.
Frequently Asked Questions
I keep seeing 15,000 remote data engineer jobs on Indeed — why is it so hard to find a genuine remote role?
The 15,000 number includes hybrid roles, location-flexible roles, and stale 2022 listings. The actual share of fully remote DE postings was approximately 2% in 2025 (n=analysis of 1,000 postings, 365 Data Science 2025), down from approximately 10% in early 2024. Genuinely remote roles concentrate at companies that have always been distributed: Coinbase, Databricks, dbt Labs, Stripe, Plaid. Filter by these rather than scrolling aggregate "remote" results.
I have 3 years of Snowflake and dbt experience — how competitive am I for senior DE roles at Databricks or Coinbase?
By the Stack-Reality Score, you are likely a Level 2 Cross-Stack Literate candidate for those companies. Databricks runs on Databricks plus Spark plus Delta Lake; Coinbase leans heavily on Spark and Kafka. Your expertise is transferable, but you will be evaluated against candidates with production Spark experience. Expect to interview at the lower end of the senior band ($147K–$170K) unless you spend 4 to 8 weeks building a portfolio project on the target stack first. Alternatively, target Snowflake-stack-aligned companies (dbt Labs, SimplePractice, Snowflake itself) where your stack scores Level 3 or 4.
How do I use the Stack-Reality Score to decide which remote DE jobs to apply for?
Score yourself against each target role's stack before applying. Level 1: do not apply blind — build a portfolio project first. Level 2: apply, but expect lower-end-of-band offers; lead with architectural understanding of the target stack. Level 3: apply with confidence; lead with metric-anchored production work. Level 4: apply, negotiate aggressively, and use second-stack experience as leverage for top-of-band compensation.
What's the actual salary for a remote senior data engineer in 2026, and does location matter?
Senior DE base ranges $147K–$218K, with Built In reporting $191,822 average base ($217,051 total comp) for the senior tier. Location matters at companies with adjusted bands — same title, $175K in San Francisco vs. $130K in Austin — and does not matter at companies with geographic-equity policies (Coinbase, Stripe, Databricks at varying tiers). Ask explicitly: "Do you adjust compensation based on employee location?"
Which companies are actually fully remote for data engineers — not just "remote-friendly"?
The genuinely-distributed list is short: Databricks, Coinbase, dbt Labs, Stripe, Plaid, Snowflake, plus a smaller set of remote-first SaaS (SimplePractice, Reddit Inc.). These companies built distributed-by-design, did not reverse course during 2024–2025 RTO mandates, and have written compensation policies around remote. Most Fortune 500 — including FAANG — are now hybrid-first with team-specific exceptions.
What's the difference between a data engineer and an analytics engineer?
A data engineer owns pipelines, infrastructure, and data movement; an analytics engineer owns transformation logic, dbt models, and the layer between the warehouse and analyst-facing tables. At sub-200-person companies the titles often blur. Both have meaningful remote availability — analytics engineering is slightly more remote-accessible because the work is dbt-and-warehouse-oriented. See our data engineer vs. data analyst breakdown.
I'm a data analyst with SQL and Python skills — what's the realistic path to a remote DE role?
Timeline: 9 to 12 months of focused effort. Stack to learn first: Snowflake plus dbt plus Airflow. Build two production-quality portfolio projects — one end-to-end pipeline and one orchestration project (Airflow DAG with retries, alerting, monitoring). Salary jump: $30K–$60K above current analyst comp once you land the first DE role.
How is AI changing what remote data engineers do day-to-day?
Boilerplate ETL writing is being automated; the LLM in your IDE writes connector code now, and that pattern accelerates through 2026 and 2027. Growing: data quality systems, observability tooling, ML feature stores, inference pipeline architecture, governance and access control. The 55% of data professionals now identifying as data engineers (up from 40% in 2021) reflects the field expanding, not contracting under automation pressure.
What salary should I ask for in a remote DE negotiation?
Anchor your counter to the upper third of the posted band — not the midpoint. If the band is $147K–$218K, counter at $195K–$210K base with rationale tied to your Stack-Reality Score and specific production work. Only 39% of engineers counter, but 50%+ of those who do receive an increase (Glassdoor 2026). Ask the three location questions before signing.
What are the must-know Python and SQL skills for a remote DE in 2026?
Python: PySpark for Databricks-stack roles; Pandas for data validation; SQLAlchemy for warehouse interaction; pytest for pipeline testing. SQL: warehouse-specific dialects matter — Snowflake SQL (clustering keys, micro-partitions), BigQuery SQL (partitioning, slot management), PostgreSQL for operational stores. The denominators: 70% (n=700/1,000) require Python; 69% (n=690/1,000) require SQL. The differentiation is what you have built with them at scale.
Start Your Remote Data Engineer Search the Right Way
The 15,000 listings on Indeed are not lying — they are mislabeling. Click through enough of them and you will find "remote" buried next to "quarterly travel to HQ" or revealed in round three. The genuinely-remote DE market concentrates at a short list of companies that built distributed by design, paid real comp for it, and never reversed course. That list is short enough to know by name.
Use the Stack-Reality Score before every application to decide whether you are competitive at the role and how to position your resume. Cross-link from this guide to our data engineer vs. data analyst comparison if you are still triangulating role fit, and to our remote data analyst roles coverage for adjacent paths. To stop manually sorting through misleading "remote" listings, Remote Job Assistant's auto-apply targets the genuinely-remote DE roles automatically and applies on your behalf.
The pipelines that move every company's most important data don't know where their engineers sit. The companies that understand that are the ones worth finding.
Ready to Find Your Remote Job?
Browse thousands of curated remote jobs or let AI apply for you.
Browse Remote JobsRelated Job Guides

Product Owner vs. Project Manager: Salary, Certs & Remote in 2026
Product Owner vs. Project Manager: 2026 salary data, CSPO vs. PMP cert costs, remote job counts, and which role pays $19K more for remote workers on average.
26 min read

Remote Program Manager Jobs: 2026 Salary & Career Guide
Remote program manager jobs pay $93K–$228K, with TPM roles hitting $160K+. Compare tracks, top companies, and skills — plus how to pass the PgM screen.
20 min read

Project Coordinator vs Project Manager: Key Differences
Project coordinator vs project manager: the $37K salary gap, day-to-day differences, and exactly how to advance from one to the other. From 847 remote postings.
25 min read